Présentation
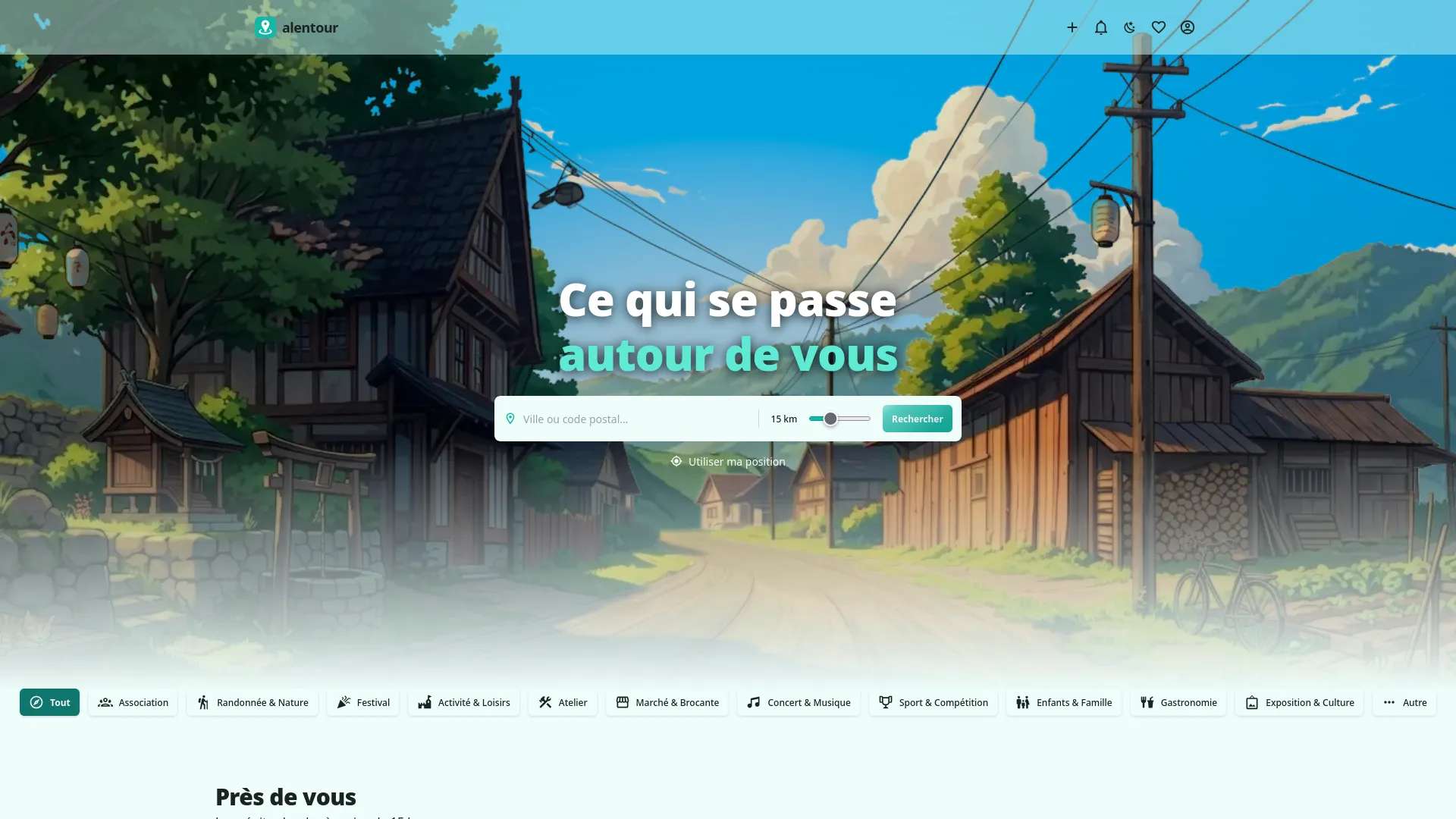
Alentour centralise les événements locaux en un seul endroit. Randonnées, marchés, fêtes de village, ateliers, activités associatives — tout ce qui se passe près de chez vous, sans avoir à fouiller dix groupes Facebook, cinq sites de mairie et autant d'affiches dans la boulangerie.
Pensé pour les petites villes autant que les grandes, pour l'association du coin autant que pour le grand rassemblement. Ce qui compte, c'est la proximité — pas la popularité ou le budget de l'organisateur.
Problématique & Approche
Tout part d'une conversation avec des amis du comité des fêtes de ma ville. Leur double problème : en tant que visiteurs, ils découvraient des événements intéressants après qu'ils soient passés. En tant qu'organisateurs, ils publiaient sur Facebook, sur le site de la commune, sur d'autres plateformes — et devaient ensuite surveiller chaque endroit séparément pour voir les questions et les retours. Deux problèmes symétriques, une même cause : l'information locale est partout, donc introuvable.
L'information locale existe. Elle est juste éparpillée partout : pages Facebook d'associations, sites de mairie souvent mal entretenus, groupes locaux, affiches physiques, plateformes régionales isolées. En 2026, on peut commander à manger en trois clics ou réserver un billet d'avion en deux minutes — mais savoir ce qui se passe à 10 km de chez soi reste un parcours du combattant.
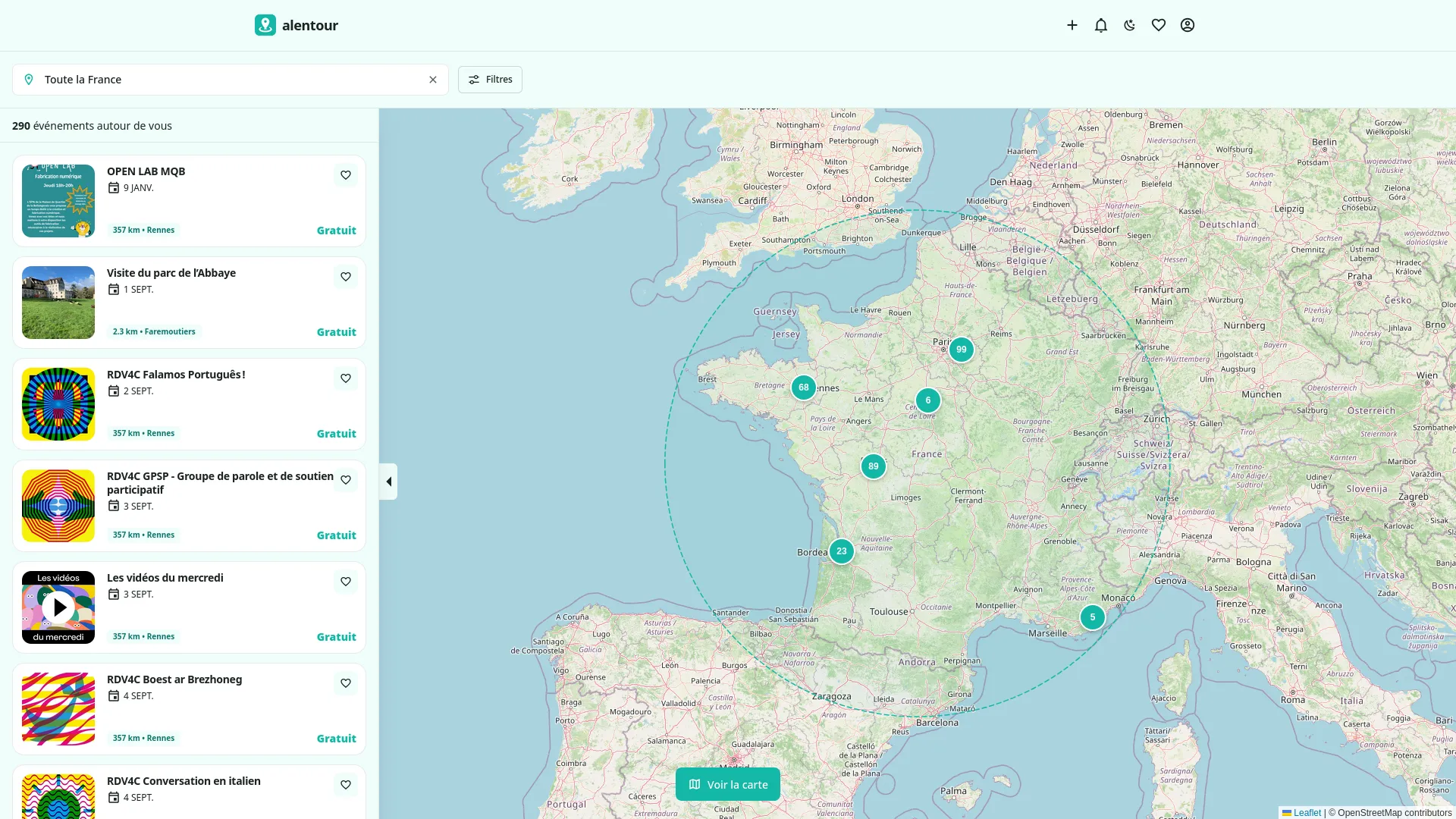
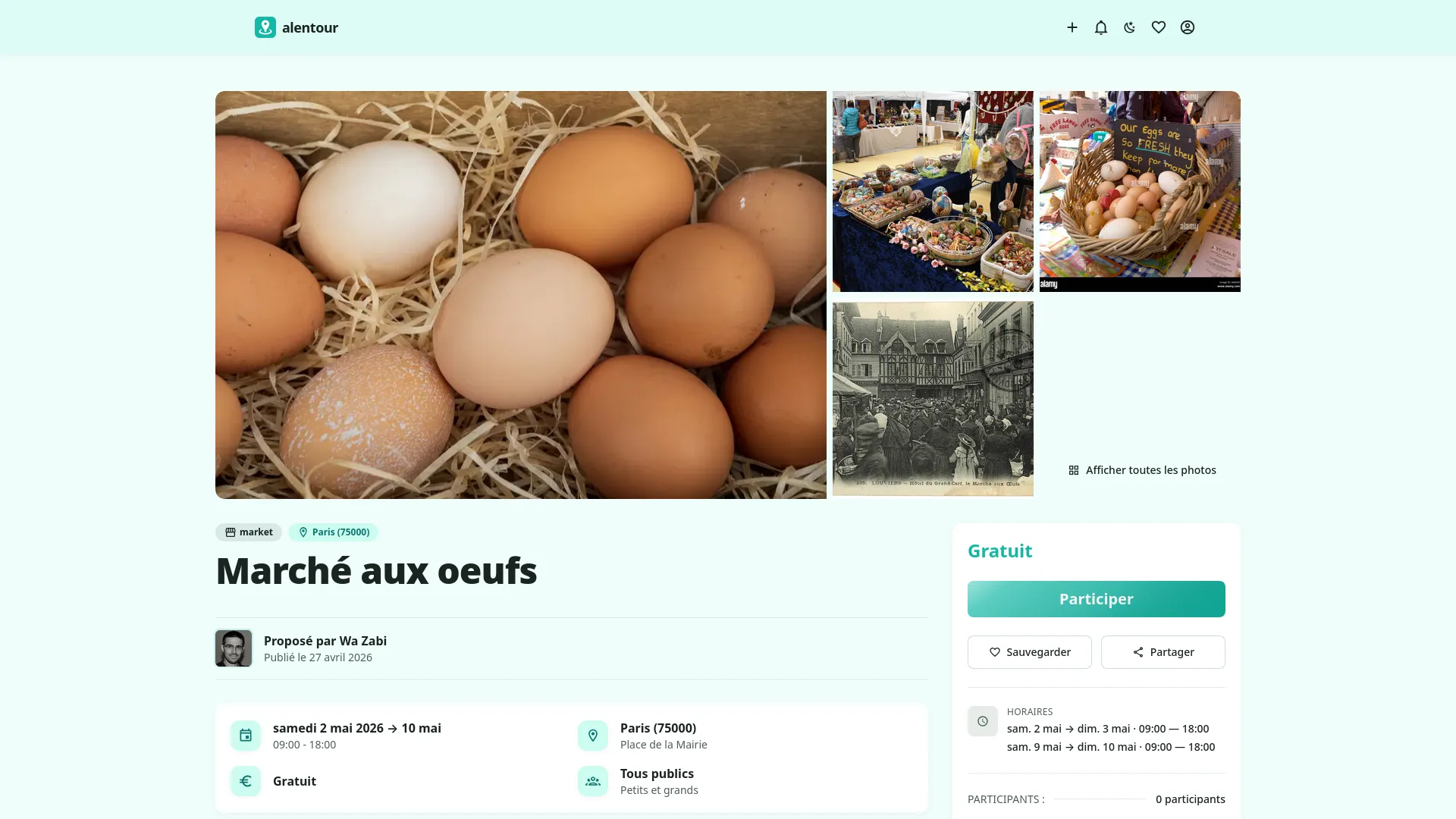
Alentour répond à ça simplement : une interface claire, une recherche par ville ou géolocalisation, des notifications quand quelque chose de nouveau apparaît dans sa zone. Et une règle de base — aucun événement n'est mis en avant selon son budget ou sa popularité. Tout est classé par date et par distance. Une petite randonnée associative ne sera jamais écrasée par un concert bien financé.
Ce que j'ai construit
Au-delà de l'affichage d'événements, Alentour embarque un système de scraping multi-sources qui agrège automatiquement les événements existants sur le web — avec redirection systématique vers la source originale, jamais de substitution. C'est une couche de découverte, pas de récupération de contenu.
Au-delà de l'affichage d'événements, Alentour embarque un système de scraping multi-sources qui agrège automatiquement les événements existants sur le web — avec redirection systématique vers la source originale, jamais de substitution. C'est une couche de découverte, pas de récupération de contenu.
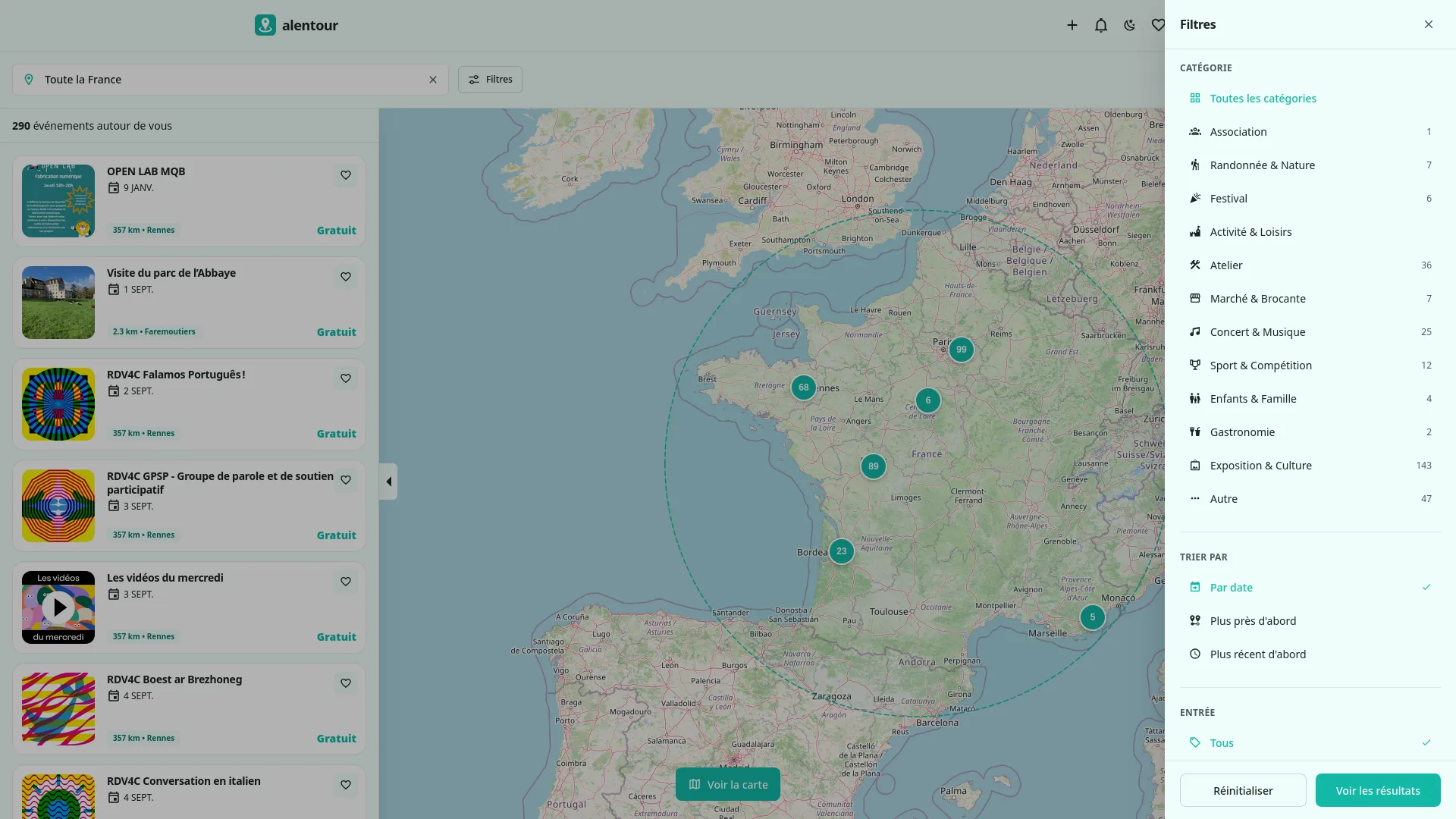
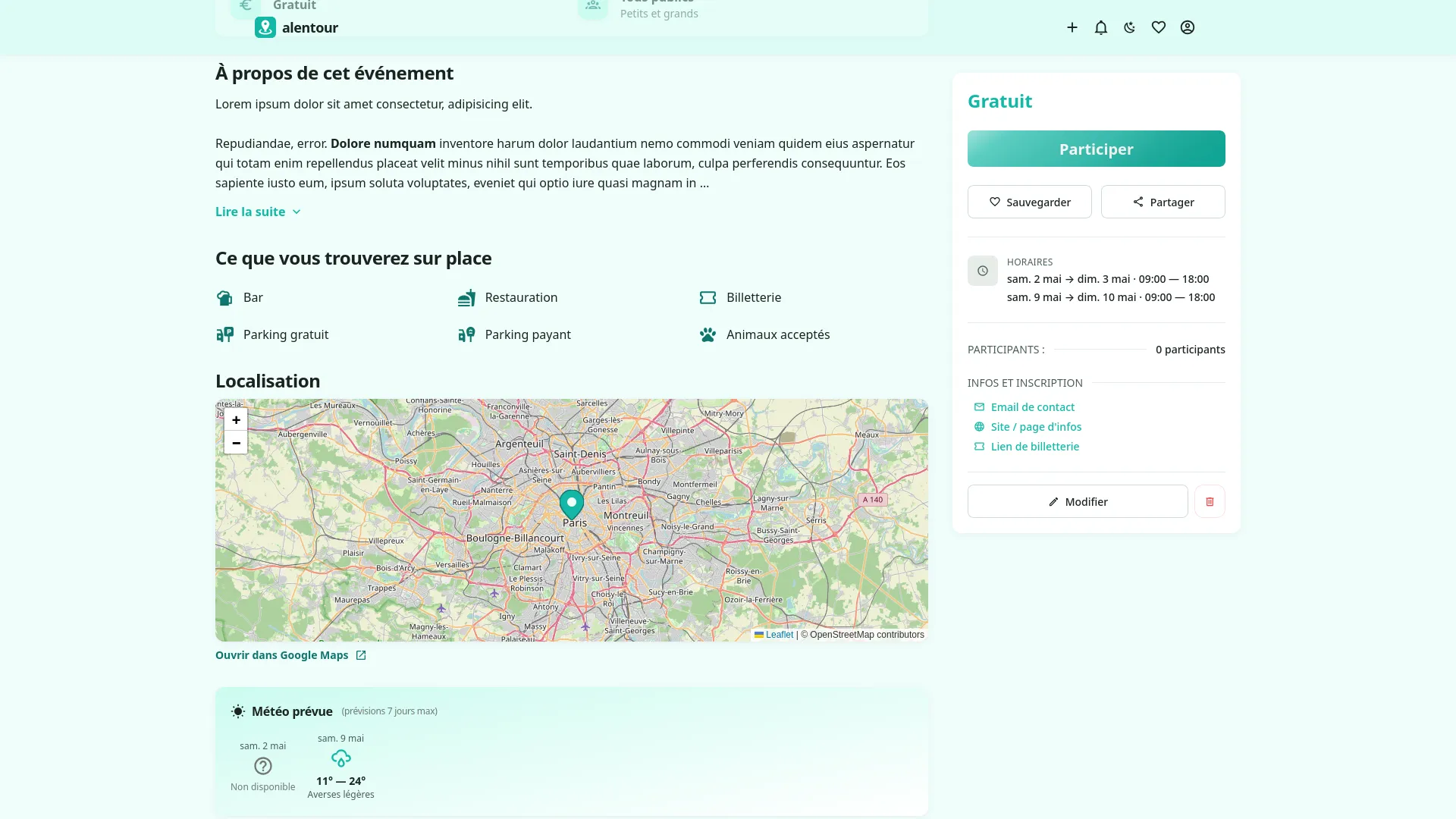
Quelques détails qui font la différence : intégration météo pour les événements à moins de 7 jours, système de villes favorites avec notifications dédiées, rayons de recherche de 5 à 30 km, sauvegarde d'événements avec rappel 3 jours et 24h avant. Et un back-office complet pour gérer les sources de scraping, les catégories, les types de public, et monitorer l'activité sans toucher à aucune donnée personnelle.
Choix techniques & approche
Vue 3, Nuxt, TypeScript, Tailwind, Supabase — avec une philosophie : tout passe par un provider pour limiter le vendor lock-in. Leaflet plutôt que Google Maps, open source et sans dépendance tarifaire à l'usage.
Le scraping a été le défi technique principal : chaque source utilise un format différent, certaines communes ont des sites modernes, d'autres des pages statiques des années 2000. J'ai dû construire plusieurs patterns d'extraction, un système de normalisation des données, et une détection de doublons. La géolocalisation des événements et l'optimisation des requêtes de proximité ont aussi demandé une vraie réflexion sur la structure des données en base.
Comme pour la majoritée de mes projets, la techno est venue après la réflexion produit et UX — pas l'inverse.
État actuel & suite
Le projet est en cours de développement actif. L'objectif actuel est de valider le concept et les usages avant d'aller plus loin. Le prochain chantier : intégrer Stripe et finaliser le modèle de tarification — publication à l'acte ou abonnement mensuel selon le volume.
Les trois premiers mois de publication seront gratuits pour accompagner le lancement. Le scraping automatique est volontairement limité pour l'instant — c'est un outil d'amorçage, pas un modèle permanent.
Collaboration IA & méthode de travail
Ce projet a été développé en collaboration étroite avec des outils IA. Pas dans une logique de simple "génère et copie-colle", mais dans un véritable échange continu : je posais les problèmes, j'analysais les options proposées, puis je faisais les choix techniques et produit.
Toute la partie réflexion, UX, design d'interface, direction artistique, architecture produit, intégration front-end et conception des fonctionnalités vient de moi. L'IA m'a servi d'accélérateur et de sparring partner — notamment sur des couches que je n'avais jamais abordées avant, comme le scraping multi-sources et la normalisation de données hétérogènes.
1 / 6